2R3
Anomalies alerting and detection
Key role(s)
Objectives
Define the monitoring to be set up
Benefits
Define the monitoring to be set up
The idea is to focus on abnormal situations of expenditure or use of resources. The following are examples of monitoring to be put in place:
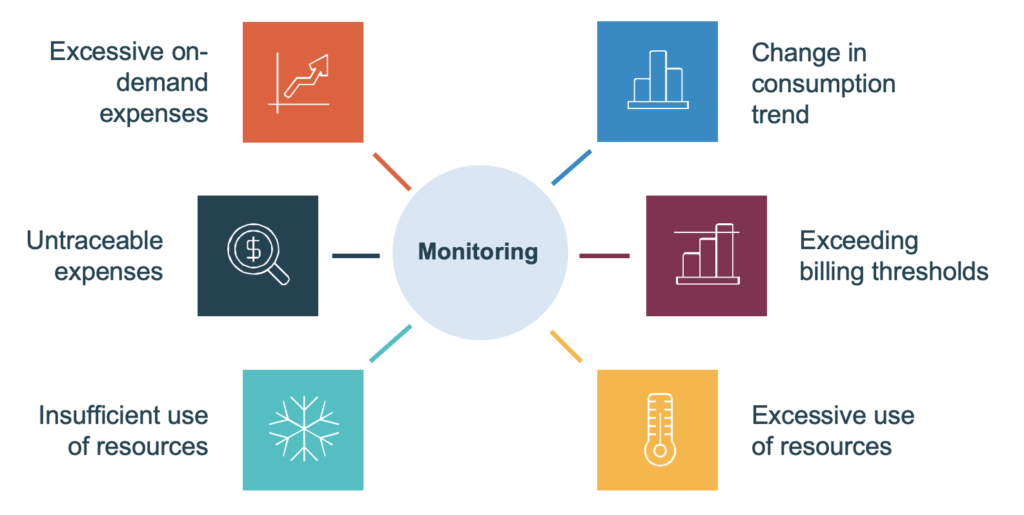
- Excessive on-demand spending by component or application
- Non-traceable expenses (i.e., expenses that cannot be clearly traced to a service or application)
- Insufficient use of resources (e.g. average CPU usage of less than 20%)
- Exessive use of resources (if we take our example from the fact that a CPU used on average at 99% can be a problem)
- Exceeding pre-defined billing thresholds for a given project or application (ensures that a simple experiment will not cost us a fortune).
- Change in the consumption trend of a resource: A sudden decrease or increase in consumption, for example
And for each event, the question of notification will have to be asked.
Email is often not the best approach. A message on Slack or equivalent may be more judicious.
In some cases, automated reporting sent once a week will be the right option. Because you also have to ask the question of frequency: Do you want to be notified in real time, every day, every week,... ?