2R3
Alerting et détection des anomalies
Rôle(s) Clé
Objectifs
Définir les surveillances à mettre en place
Bénéfices
Eviter les incidents liés aux dépenses
L'idée est de se concentrer sur les situations anormales de dépenses ou d’utilisation des ressources. Voici des exemples de surveillance à mettre en place :
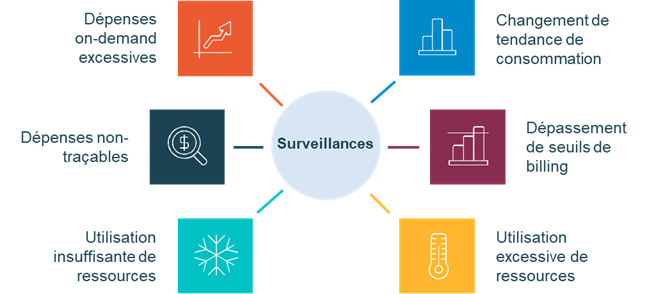
- Dépenses “on-demand” excessives par composant ou application
- Dépenses non-traçables (c’est-à-dire qui ne peuvent être rattachées clairement à un service ou une application)
- Utilisation insuffisante de ressources (par exemple un % de CPU moyenne utilisée inférieure à 20%)
- Utilisation exessive de ressources (si l’on reprend notre exemple le fait qu’une CPU utilisée en moyenne à 99% peut être un problème)
- Dépassement de seuils de billing pré-définis pour un projet ou une application donnés (permet notamment de s’assurer qu’une simple expérimentation ne va pas nous coûter une fortune)
- Changement de tendance de consommation d’une ressource : Une baisse ou une augmentation soudaine de consommation par exemple
Et pour chaque événement il faudra se poser la question de la notification.
L’email n’est souvent pas la meilleure approche. Un message sur Slack ou équivalent peut être plus judicieux.
Dans certains cas, le reporting automatisé envoyé une fois par semaine sera la bonne option. Car il faut aussi se poser la question de la fréquence : Veut-on être prévenu en temps réel ? Tous les jours, toutes les semaines,…